In this post, we'll dig into the basic collections that we use day to day java programming. I'll hope the this post will help to understand and remember the concept of collection framework.

What is Collection?
In simple term, you can say collection is a container — is simply an object that groups multiple elements into a single unit.
For instance, Collection correspond to a bag. Typically, they represent data items that form a natural group such as a collection of cards,a collection of letters, and a mapping of names to phone numbers.
The Collections Framework in the java.util package is loaded with interfaces and utilities.
What Is a Collections Framework?
A collections framework is a unified architecture for representing and manipulating collections. All collections frameworks contain the following:
Key Interfaces and Classes of the Collections Framework

Key Classes of the Collections Framework

Collections come in four basic flavors


A List cares about the index.
An ordered collection (also known as a sequence). The user of this interface has precise control over where in the list each element is inserted. The user can access elements by their integer index (position in the list), and search for elements in the list.
The List interface provides a special iterator, called a ListIterator, that allows element insertion and replacement, and bidirectional access in addition to the normal operations that the Iterator interface provides. A method is provided to obtain a list iterator that starts at a specified position in the list.
Category of List operation
Positional access — manipulates elements based on their numerical position in the list

==============================================================================================
Arraylist
This is Resizable-array implementation of the List interface
We'll see fail-fast in the following example.


 Choose this over a LinkedList when you need fast iteration but aren't as likely to be doing a lot of insertion and deletion
Choose this over a LinkedList when you need fast iteration but aren't as likely to be doing a lot of insertion and deletion
==============================================================================================
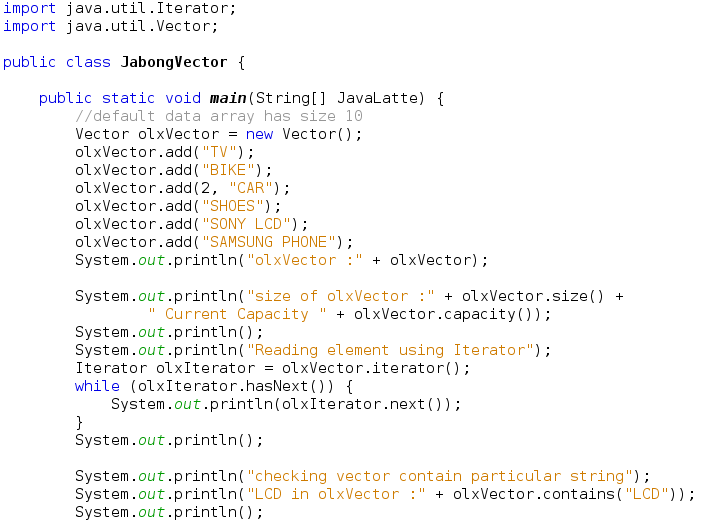
Vector
 Output:
Output:

Difference between ArrayList and Vector? *interview question
==============================================================================================
LinkedList
We'll see few methods example demo

 Output:
Output:

Note that this implementation is not synchronized. If multiple threads access a linked list concurrently, and at least one of the threads modifies the list structurally, it must be synchronized externally
A palindrome is a word or phrase that reads the same forward and backward. For instance, "abcba". We'll see how to do this with the help of LinkedList and ListIterator
Example of ListIterator

Difference between ArrayList and LinkedList? *interview question

A Set cares about uniqueness—it doesn't allow duplicates. Your good friend the equals() method determines whether two objects are identical.
HashSet
 Output
Output
LinkedHashSet

Output

TreeSet
The TreeSet is one of two sorted collections (the other being TreeMap). It uses a Red-Black tree structure, and guarantees that the elements will be in ascending order, according to natural order.
The behavior of a set is well-defined even if its ordering is inconsistent with equals; it just fails to obey the general contract of the Set interface.
Few functions of TreeSet with the help of example


Output




Output

Hashtable

 Output
Output
 ==============================================================================================
==============================================================================================
LinkedHashMap
TreeMap


Output

The iterators returned by this all the above class's iterator methods are fail-fast as you have already seen in the above examples.
Related Post
4 ways to iterate over Map in java
120+ Core java interview Question including Collection related also
7 new feature of Java 7
Garbage Collection from Interview perspective
What is Collection?
In simple term, you can say collection is a container — is simply an object that groups multiple elements into a single unit.
For instance, Collection correspond to a bag. Typically, they represent data items that form a natural group such as a collection of cards,a collection of letters, and a mapping of names to phone numbers.
- Like C++'s Standard Template Library (STL)
- Can grow as necessary
- Contain only Objects
- Heterogeneous
- Can be made thread safe
- Can be made not-modifiable
There are really three overloaded uses of the word "collection"
- collection(lowercase c), which represents any of the data structures in which objects are stored and iterated over.
- Collection (capital C), which is actually the java.util.Collection interface from which Set, List, and Queue extend. (That's right, extend, not implement. There are no direct implementations of Collection.)
- Collections (capital C and ends with s) is the java.util.Collections class that holds a pile of static utility methods for use with collections
What Is a Collections Framework?
A collections framework is a unified architecture for representing and manipulating collections. All collections frameworks contain the following:
- Interfaces Represent different types of collections, such as sets, lists, and maps. These interfaces form the basis of the framework.
- Implementations Primary implementations of the collection interfaces.
- Algorithms Static methods that perform useful functions on collections, such as sorting a list.
Advantages of a collections framework
- A usable set of collection interfaces : By implementing one of the basic interfaces -- Collection, Set, List, or Map -- you ensure your class conforms to a common API and becomes more regular and easily understood
- A basic set of collection implementations : Using an existing, common implementation makes your code shorter and quicker to download. Also, using existing Core Java code core ensures that any improvements to the base code will also improve the performance of your code.
- Reduces programming effort by providing data structures and algorithms so you don't have to write them yourself.
- Provides interoperability between unrelated APIs by establishing a common language to pass collections back and forth.
- Reduces the effort required to learn APIs by requiring you to learn multiple ad hoc collection APIs.
- Reduces the effort required to design and implement APIs by not requiring you to produce ad hoc collections APIs.
Collection is an interface with declarations of the methods common to most collections including add(), remove(), contains(), size(), and iterator().
Key Interfaces and Classes of the Collections Framework
Key Classes of the Collections Framework
Collections come in four basic flavors
- Lists Lists of things (classes that implement List)
- Sets Unique things (classes that implement Set).
- Maps Things with a unique ID (classes that implement Map).
- Queues Things arranged by the order in which they are to be processed.
List interface
A List cares about the index.
An ordered collection (also known as a sequence). The user of this interface has precise control over where in the list each element is inserted. The user can access elements by their integer index (position in the list), and search for elements in the list.
- Lists typically allow duplicate elements
- Access to elements via indexes, like arrays add (int, Object), get(int), remove(int), set(int, Object)
- Search for elements : indexOf(Object), lastIndexOf(Object)
- Specialized Iterator, call ListIterator
- Extraction of sublist : subList(int fromIndex, int toIndex)
- add(Object) adds at the end of the list
- remove(Object) removes at the start of the list.
- list1.equals(list2) the ordering of the elements is taken into consideration
- Extra requirements to the method hashCode
list1.equals(list2) implies that list1.hashCode()==list2.hashCode()
The List interface provides a special iterator, called a ListIterator, that allows element insertion and replacement, and bidirectional access in addition to the normal operations that the Iterator interface provides. A method is provided to obtain a list iterator that starts at a specified position in the list.
Category of List operation
Positional access — manipulates elements based on their numerical position in the list
- Object get(int index);
- Object set(int index, Object element); // Optional
- void add(int index, Object element); // Optional
- Object remove(int index); // Optional
- abstract boolean addAll(int index, Collection c); // Optional
Search — searches for a specified object in the list and returns its numerical position.
- int indexOf(Object o);
- int lastIndexOf(Object o);
Iteration — extends Iterator semantics to take advantage of the list's sequential nature
- ListIterator listIterator();
- ListIterator listIterator(int index);
Range-view — performs arbitrary range operations on the list.
- List subList(int from, int to);
==============================================================================================
Arraylist
This is Resizable-array implementation of the List interface
- ArrayList is an array based implementation where elements can be accessed directly via the get and set methods.
- Default choice for simple sequence.
- It gives you fast iteration and fast random access
- It is an ordered collection (by index), but not sorted
Output :
==============================================================================================
Vector
- A Vector is basically the same as an ArrayList, but Vector methods are synchronized for thread safety.
- You'll normally want to use ArrayList instead of Vector because the synchronized methods add a performance hit you might not need.
Difference between ArrayList and Vector? *interview question
- Vectors are synchronized, ArrayLists are not.
If multiple threads access an ArrayList concurrently then we must externally synchronize the block of code which modifies the list either structurally or simply modifies an element. Structural modification means addition or deletion of element(s) from the list. Setting the value of an existing element is not a structural modification. - Data Growth Methods
A Vector defaults to doubling the size of its array, while the ArrayList increases its array size by 50 percent.
Depending on how you use these classes, you could end up taking a large performance hit while adding new elements. It's always best to set the object's initial capacity to the largest capacity that your program will need.
==============================================================================================
LinkedList
- A LinkedList is ordered by index position, like ArrayList, except that the elements are doubly-linked to one another.
- This linkage gives you new methods (beyond what you get from the List interface) for adding and removing from the beginning or end, which makes it an easy choice for implementing a stack or queue.
We'll see few methods example demo
Note that this implementation is not synchronized. If multiple threads access a linked list concurrently, and at least one of the threads modifies the list structurally, it must be synchronized externally
A palindrome is a word or phrase that reads the same forward and backward. For instance, "abcba". We'll see how to do this with the help of LinkedList and ListIterator
Example of ListIterator
Difference between ArrayList and LinkedList? *interview question
LinkedList and ArrayList are two different implementations of the List interface.
- LinkedList implements it with a doubly-linked list.
- ArrayList implements it with a dynamically resizing array.
- LinkedList<E> allows for constant-time insertions or removals using iterators, but only sequential access of elements. In other words, you can walk the list forwards or backwards, but finding a position in the list takes time proportional to the size of the list.
- ArrayList<E>, on the other hand, allow fast random read access, so you can grab any element in constant time. But adding or removing from anywhere but the end requires shifting all the latter elements over, either to make an opening or fill the gap.
- Use LinkedList when you need fast insertion and deletion whereas which is slow in ArrayList
- Use ArrayList when you need fast iteration and fast random access whereas which is slow in LinkedList
==============================================================================================
Set Interface
HashSet
- A HashSet is an unsorted, unordered Set.
- It uses the hashcode of the object being inserted, so the more efficient your hashCode() implementation the better access performance you'll get.
- Use this class when you want a collection with no duplicates and you don't care about order when you iterate through it.
- This class permits the null element
- If you attempt to add an element to a set that already exists in the set, the duplicate element will not be added, and the add() method will return false
This class offers constant time performance for the basic operations (add, remove, contains and size), assuming the hash function disperses the elements properly among the buckets
==============================================================================================

LinkedHashSet
- A LinkedHashSet is an ordered version of HashSet that maintains a doubly-linked List across all elements.
- Use this class instead of HashSet when you care about the iteration order.
- When you iterate through a HashSet the order is unpredictable, while a LinkedHashSet lets you iterate through the elements in the order in which they were inserted.
- permits null elements
It provides constant-time performance for the basic operations (add, contains and remove), assuming the hash function disperses elements properly among the buckets.
As you have already seen in the above program that order is unpredictable, now we'll in the below program LinkedHashSet maintain insertion order.
Note HashSet, LinkedHashSet implementation is not synchronized. If multiple threads access a hash set concurrently, and at least one of the threads modifies the set, it must be synchronized externally
Difference between HashSet and LinkedHashSet? *interview question
LinkedHashSet performance is likely to be just slightly below that of HashSet, due to the added expense of maintaining the linked list with one exception:- Iteration over a LinkedHashSet requires time proportional to the size of the set, regardless of its capacity.
- Iteration over a HashSet is likely to be more expensive, requiring time proportional to its capacity.
==============================================================================================
TreeSet
The TreeSet is one of two sorted collections (the other being TreeMap). It uses a Red-Black tree structure, and guarantees that the elements will be in ascending order, according to natural order.
- Guarantees log(n) time cost for the basic operations (add, remove and contains).
- Offers a few handy methods to deal with the ordered set like first(), last(), headSet(), and tailSet() etc
- Tress set will not allow null object. if you try to add null value i will be throw null pointer exception
Note that the ordering maintained by a set must be consistent with equals if it is to correctly implement the Set interface.
This is so because the Set interface is defined in terms of the equals operation, but a TreeSet instance performs all element comparisons using its compareTo (or compare) method, so two elements that are deemed equal by this method are, from the standpoint of the set, equal.
The behavior of a set is well-defined even if its ordering is inconsistent with equals; it just fails to obey the general contract of the Set interface.
Few functions of TreeSet with the help of example
- ceiling(E e) : Returns the least element in this set greater than or equal to the given element, or null if there is no such element.
- floor(E e) : Returns the greatest element in this set less than or equal to the given element, or null if there is no such element.
- higher(E e) : Returns the least element in this set strictly greater than the given element, or null if there is no such element.
- lower(E e) : Returns the greatest element in this set strictly less than the given element, or null if there is no such element.
- SortedSet<E> headSet(E toElement) : Returns a view of the portion of this set whose elements are strictly less than toElement.
- SortedSet<E> tailSet(E fromElement) : Returns a view of the portion of this set whose elements are greater than or equal to fromElement.
Output
Difference between HashSet and TreeSet? *interview question
HashSet- Hash set allow null object
- class offers constant time performance for the basic operations (add, remove, contains and size).
- Does not guarantee that the order of elements will remain constant over time
- Iteration performance depends on the initial capacity and the load factor of the HashSet.
- It's quite safe to accept default load factor but you may want to specify an initial capacity that's about twice the size to which you expect the set to grow
TreeSet
- Tress set will not allow null object .if you try to add null value i will be throw null pointer exception
- log(n) time cost for the basic operations (add, remove and contains).
- elements of set will be sorted (ascending, natural, or the one specified by you via it's constructor)
- Doesn't offer any tuning parameters for iteration performance
==============================================================================================
Map Interface
- A Map cares about unique identifiers.
- The Map implementations let you do things like search for a value based on the key, ask for a collection of just the values, or ask for a collection of just the keys.
- Like Sets, Maps rely on the equals() method to determine whether two keys are the same or different.
- A map cannot contain duplicate keys; each key can map to at most one value.
- The Map interface provides three collection views, which allow a map's contents to be viewed as a set of keys, collection of values, or set of key-value mappings.
- Great care must be exercised if mutable objects are used as map keys. The behavior of a map is not specified if the value of an object is changed in a manner that affects equals comparisons while the object is a key in the map
HashMap
- The HashMap gives you an unsorted, unordered Map, it does not guarantee that the order will remain constant over time.
- HashMap allows one null key and multiple null values in a collection
- When you need a Map and you don't care about the order (when you iterate through it), then HashMap is the way to go; the other maps add a little more overhead
- The more efficient your hashCode() implementation, the better access performance you'll get.
- The HashMap class is roughly equivalent to Hashtable, except that it is unsynchronized and permits nulls.
- This implementation provides constant-time performance for the basic operations (get and put), assuming the hash function disperses the elements properly among the buckets.
An instance of HashMap has two parameters that affect its performance: initial capacity and load factor. The capacity is the number of buckets in the hash table, and the initial capacity is simply the capacity at the time the hash table is created. The load factor is a measure of how full the hash table is allowed to get before its capacity is automatically increased. When the number of entries in the hash table exceeds the product of the load factor and the current capacity, the hash table is rehashed (that is, internal data structures are rebuilt) so that the hash table has approximately twice the number of buckets.
As a general rule, the default load factor (.75) offers a good tradeoff between time and space costs.
As a general rule, the default load factor (.75) offers a good tradeoff between time and space costs.
Output
==============================================================================================
Hashtable
- Just as Vector is a synchronized counterpart to the sleeker, more modern ArrayList, Hashtable is the synchronized counterpart to HashMap.
- Remember that you don't synchronize a class, so when we say that Vector and Hashtable are synchronized, we just mean that the key methods of the class are synchronized
How Hashtable differ from HashMap? *interview question
- Hashtable doesn't let you have anything that's null whereas HashMap allows one null key and multiple null values in a collection
- HashMap is not Synchronized where as HashTable is Synchronized.
- HashMap cannot be shared with multiple thread without proper synchronization where HashTable is thread safe and can be shared between multiple thread
- Iterator in HashMap if fail fast where as Enumerator in HashTable is not fail fast
LinkedHashMap
- Like its Set counterpart, LinkedHashSet, the LinkedHash- Map collection maintains insertion order (or, optionally, access order).
- Slower than HashMap for adding and removing elements, you can expect faster iteration with a LinkedHashMap.
Example will be same as above.
TreeMap
- TreeMap is a sorted Map.
And you already know that by default, this means "sorted by the natural order of the elements.
Like TreeSet, TreeMap lets you define a custom sort order (via a Comparable or Comparator) when you construct a TreeMap, that specifies how the elements should be compared to one another when they're being ordered
Output
The iterators returned by this all the above class's iterator methods are fail-fast as you have already seen in the above examples.
Related Post
4 ways to iterate over Map in java
120+ Core java interview Question including Collection related also
7 new feature of Java 7
Garbage Collection from Interview perspective
If you know anyone who has started learning Java, why not help them out! Just share this post with them. Thanks for studying today!...
Map is not a apart Of Collection.The content is really good carrying all the useful information.
ReplyDeleteNice articles.You are explain very well.java collection programs http://www.javaproficiency.com/2015/05/java-collections-framework-tutorials.html
ReplyDelete"I very much enjoyed this article.Nice article thanks for given this information. i hope it useful to many pepole.php jobs in hyderabad.
ReplyDelete"
ReplyDeletegraphic design stock images
Click here for get more information about it - http://mediastockerz.com/gallery/Vectors/14/page1/
I am really impressed with your efforts and really pleased to visit this post.
ReplyDeleteOracle DBA Training Self Placed Videos
Splunk Training Self Placed Videos
Sap BW on Hana Training Self Placed Videos
Sap QM Training Self Placed Videos
Oracle Rac Training Self Placed Videos
Excellent post!!!. The strategy you have posted on this technology helped me to get into the next level and had lot of information in it.
ReplyDeleteDotnet Online Training
PHP Online Training
Qlikview Online Training
r-programming Online Training
Good Post! Thank you so much for sharing this pretty post, it was so good to read and useful to improve my knowledge as updated one, keep blogging.
ReplyDeleteSharepoint Training From India
Sccm2016 Training From India
"I very much enjoyed this article.Nice article thanks for given this information. i hope it useful to many pepole.php jobs in hyderabad.
ReplyDeleteSAP GTS Classes
Oracle BPM Classes
The blog is good, but the blue font on black background just got me a headache 😣🙄
ReplyDeleteThe The quickbooks payroll support telephone number team at site name is held responsible for removing the errors that pop up in this desirable software. We take care of not letting any issue are available in betwixt your work and trouble you in undergoing your tasks. Many of us resolves all of the QuickBooks Payroll issue this sort of a fashion that you'll yourself feel that your issue is resolved without you wasting the time into it. We take toll on every issue making use of our highly trained customer support
ReplyDeleteteam at site name is held responsible for removing the errors that pop up in this desirable software. We take care of not letting any issue are available in betwixt your work and trouble you in undergoing your tasks. Many of us resolves all of the QuickBooks Payroll issue this sort of a fashion that you'll yourself feel that your issue is resolved without you wasting the time into it. We take toll on every issue making use of our highly trained customer support
The Guidance And Support System QuickBooks Enterprise Tech Support Is Dedicated To Provide Step-By-Step Approaches To The Issues Encountered By Existing And New Users.
ReplyDeletefacing problem while upgrading QuickBook Customer Support Number towards the newest version. There could be trouble while taking backup of your respective data, you may possibly never be in a position to open your organization file on multi-user mode.
ReplyDeleteQuickBooks Support Phone Number troubleshooting team will allow you to in eradicating the errors which will pop-up very often. There clearly was common conditions that are encountered on daily basis by QuickBooks users.
ReplyDeletesuccessfully. The smart accounting software is richly featured with productive functionalities that save time and accuracy of the work. As it is accounting software, from time to time you may have a query and will seek assistance. This is the reason why QuickBooks has opened toll free Quickbooks Support Phone Number. For telephone assistance just call or email to support team.
ReplyDeleteNow it is possible for virtually any user to reach us in case there is performance error in your QuickBooks. It is possible to reach us at QuickBooks 2018 Tech Support number. If you should be facing problem in upgrading, downgrading to various versions of one's QuickBooks, you can reach us at QuickBooks Tech Support Phone Number.
ReplyDeleteAs QuickBooks Premier has various industry versions such as for example retail, manufacturing & wholesale, general contractor, general business, Non-profit & Professional Services, there was innumerous errors that will create your task quite troublesome. At QuickBooks Support Number, you will find solution each and every issue that bothers your projects and creates hindrance in running your company smoothly.
ReplyDeleteQuickBooks Support phone number makes all the process a lot more convenient and hassle free by solving your any QuickBooks Tech Support Number issues and error in only a person call.
ReplyDeleteNo Tax penalty guaranteed: If the info you provide is perhaps all correct with QuickBooks Payroll Support fund is enough if so your whole taxes should be paid on time that may help help save you from virtually any penalty.
ReplyDeleteIf the information you provide is probably all correct along with your fund is sufficient in that case your complete taxes should be paid on time that may help save you from virtually any penalty.QuickBooks Payroll Support Phone Number
ReplyDeleteThere are tons many additional options that come with QuickBooks Support Number which have shown great results within the development of any business. We now have a team of supremely talented support executives at Quickbooks Premier Support USA that assist you in landing out of all the QuickBooks Premier along with Premier Plus issues. QuickBooks Support comprises of all features of QuickBooks Premier in addition with some added security that enables you to have a computerized backup of your data.
ReplyDeleteprovides on demand priority support each and every and each customer without compromising with all the quality standards. You named a blunder and we also have the clear answer, this can be essentially the most luring features of QuickBooks Enterprise Support Phone Number available on a call at .You can quickly avail our other beneficial technical support services easily once we are merely a single call definately not you.
ReplyDeleteQuickBooks Enterprise Support Phone Number may be the biggest selling desktop and online software around the world. The application has transformed and helped small & medium sized companies in lots of ways and managed their business successfully.
ReplyDeleteA QuickBooks payroll service is a site you can activate by taking the subscription ensure it is easy when it comes to top top features of Payroll in your QuickBooks Payroll Support Number desktop software.
ReplyDeleteSignificant quantity of features from the end any kind of to guide both both you and contribute towards enhancing your business. Let’s see what QuickBooks Enterprise Support Phone number is mostly about.
ReplyDeleteIf you should be a QuickBooks POS Users having difficulty in your QuickBooks you can easily reach us at QuickBooks Tech Support Number to receive support from our dedicated team.We have a different team to serve the QuickBooks POS users. Our POS Support team will help you out 24X7 with your entire QuickBooks POS.
ReplyDeleteIf you're in hurry and business goes down because of the QB error it is possible to ask for Quickbooks Consultants or Quickbooks Proadvisors . If you'd like to consult with the QuickBooks experts than Quickbooks Support is actually for you !
ReplyDeleteYou don’t have to strain yourself concerning the safety and privacy of one's data as this issue may be resolved with the aid of Intuit QuickBooks Support channel at toll-free number in minimum time. There are certain possible reasons for this issue.
ReplyDeleteAs QuickBooks Support Phone Number +1-877-277-3228 Premier has various industry versions such as for example retail, manufacturing & wholesale, general contractor, general business, Non-profit & Professional Services,
ReplyDeleteQuickBooks is a well regarded accounting software that encompasses nearly every element of accounting, from the comfort of business-type to a variety of preferable subscriptions. https://www.getsupportphonenumber.us/quickbooks-enterprise-support-number/ team works on finding out of the errors that could pop up uninvitedly and bother your projects. Their team works precisely and carefully to pull out most of the possible errors and progresses on bringing them to surface. They have a separate research team this is certainly focused and desperate to work tirelessly in order to showcase their excellent technical skills in addition to to contribute in seamless flow of their customers business.
ReplyDeleteEither it is day or night, we offer hassle-free tech support team for https://www.fixaccountingerror.com/ and its particular associated software in minimum possible time.
ReplyDeleteQuickBooks does provide you all the business related QuickBooks Support Number services whether they’re attached with payroll or accounting management of your business, but some errors you can face while you are running the QuickBooks software.
ReplyDeleteYou might be always able to relate with us at our QuickBooks Toll Free Phone Number to extract the very best support services from our highly dedicated and supportive QuickBooks Support executives at any point of time as all of us is oftentimes prepared to work with you. Most of us is responsible and makes sure to deliver hundred percent assistance by working 24*7 to suit your needs. Go ahead and mail us at our quickbooks support email id whenever you are in need. You could reach us via call at our toll-free number.
ReplyDeleteSince the renovation and development of printer has been done with human effort, it is quite obvious to arrival of error and malfunction in it. This Contact HP Printer Support critical business scene creates some turmoil in one’s life.
ReplyDeleteQuickBooks Payroll Technical Support square measure obtainable round the clock to resolve your entire queries and assist you to take your business to new heights.
ReplyDeleteWe have a team this is certainly extremely supportive and customer friendly. Our customer service executives at QuickBooks Payroll Support Phone Number try not to hesitate from putting extra efforts to provide you with relief from the troubles due to QB Payroll errors.
ReplyDeleteQuickBooks Payroll has emerged the best accounting software that has had changed the meaning of payroll. QuickBooks Payroll Helpline Number could be the team that provide you Quickbooks Payroll Support. This software of QuickBooks comes with various versions and sub versions. Online Payroll and Payroll for Desktop may be the two major versions and they are further bifurcated into sub versions. Enhanced Payroll and Full-service payroll are encompassed in Online Payroll whereas Basic, Enhanced and Assisted Payroll come under Payroll for Desktop.
ReplyDeleteComes with a lovely lot of accounting versions, viz., QuickBooks Pro, QuickBooks Premier, QuickBooks Enterprise, QuickBooks POS, QuickBooks Mac, QuickBooks Windows, and QuickBooks Customer Support Number, QuickBooks is becoming a dependable accounting software that one may tailor as per your industry prerequisite.
ReplyDeleteWell! If you’re not in a position to customize employee payroll in QuickBooks Payroll Support Phone Number as well as result in the list optimally, in QB and QB desktop, then read the description ahead. Here, you'll get the determination of all sort of information everything you’ve as it's needed for assisting the setup process with comfort.
ReplyDeleteWe now have trained staff to soft your issue. Sometimes errors may possibly also happen as a result of some small mistakes. Those are decimals, comma, backspace, etc. Are you go through to cope with QuickBooks Support Phone Number? If you don't, we have been here that will help you.
ReplyDeleteSeeking support and assistance over the phone Support for QuickBooks Payroll Support Number is most frequently availed by business people and individuals through telephonic support.
ReplyDeleteQuickBooks Enterprise Support Number provides end-to end business accounting experience. With feature packed tools and features, this computer software is with the capacity of managing custom reporting, inventory, business reports etc.
ReplyDeleteQuickBooks Venture Software Program is the most reliable bookkeeping software application for medium-sized company. You can likewise utilize this variation for small business as well as 5 individuals can utilize it at the very same time. Right here, we will certainly go over concerning Quickbooks enterprise support Phone number +1(833)400-1001 for Support of QuickBooks Business version of QuickBooks Bookkeeping and also financial software program.
ReplyDeleteExactly How Does QuickBooks Business Support You?
QuickBooks Enterprise is of the most effective version of QuickBooks Software where as much as 30 customers can work at the very same time and also can videotape 1 GB dimension or even more of information on the system. This edition has functions such as improved audit trail, the alternative of appointing or restricting customer approval. It provides the ability to disperse management features to other customers making use of the program. QuickBooks Venture individuals can run into some concerns while making use of the software application. In these cases, you require to connect to Quickbooks enterprise support number +1(833)400-1001 for assistance. The QuickBooks Pro consultants are working 24 × 7 to provide appropriate and also quick resolution all type of concerns associated with QuickBooks.
QuickBooks Business provides support to your company in different ways. Intuit has equipped QuickBooks with all the sophisticated functions of accounting as well as monetary management based on the need of consumers. For more information on features of QuickBooks Enterprise, You can connect with Quickbooks enterprise support +1(833)400-1001. Several of them are listed below:
QuickBooks Company data can be conveniently moved.
Movement of customer accounts from older variation to an upgraded version is quickly feasible.
Customized reports developed in older version such as invoices, stocks, and so on can likewise be quickly relocated to updated versions.
The user-interface in Business similar to Pro or Premier version. So, you do not need to bother with functionality.
In this edition, you can also attach QuickBooks Venture to remote employees like Microsoft home windows terminal services or satellite workplaces delivering high efficiency in genuine time.
QuickBooks Business has a special function called as Audit trail tracks the deals that have been gone into, modified or erased likewise it has security against deceptive deals or duplicate entrances. Thus it lowers the time as well as energy which we spent on examining modifications made on your primary data documents. For additional information on QuickBooks Venture Support, You can likewise reach out to.
If you would like any help for QuickBooks errors from customer care to obtain the treatment for these errors and problems, it really is an easy task to experience of QuickBooks Support Phone Number in order to find instant advice about the guidance of your technical experts.
ReplyDeleteAs company file plays a truly crucial role in account management, such that QuickBooks Support Phone Number becomes a little tough to identify. File corruption issue is a bit tricky, however, you certainly will overcome it for very long depending on the 2nd instances.
ReplyDeleteIntuit publicized the production of QuickBooks 2015 with types that users have been completely demanding through the past versions. Amended income tracker, pinned notes, better registration process and understandings on homepage are among the list of general alterations for most versions of QuickBooks 2015. It can help for QuickBooks Enterprise Support Phone Number to obtain technical help & support for QuickBooks.
ReplyDeleteMost of the QuickBooks Support Phone Number above has a certain use. People working together with accounts, transaction, banking transaction need our service. Some of you are employing excel sheets for a couple calculations.
ReplyDeleteVirtually every Small And Medium Company Has Become Using QuickBooks Enterprise And Thus Errors And Problems Pertaining To It May Be Often Seen. These Problems And Troubleshooted By The Expert And Technical Team Of https://www.errorsupportnumber.com/quickbooks-enterprise-support-number/ Enables You To Contact. Commercial And Finance Operating Bodies Usually Avail The Services Of The Quickbook Enterprise Support Because They Are In Continuous Utilization Of Workbook, Sheets, Account Records, And Payroll Management Sheets. While QuickBooks Offers Multiple Financial Needs And Advantageous Assets To Its Users, QuickBooks Enterprise Support Number Helps Its User To Resolve Any Type Of Issue Generated.
ReplyDeleteConcerning easy, can you start supposing like lack of usefulness and flexibility yet this is to ensure that QuickBooks Support Phone Number has emphasize wealthy accounting programming? Thus, this item package can without much stretch handle the demands of growing associations.
ReplyDeleteAre you wandering here and there in order to search for the correct means to run the QuickBooks Enterprise software for your business? We have come with a lot of permanent solutions to fix your problems in a few seconds with an ideal QuickBooks Enterprise Support Phone Number. Just dial our QuickBooks Enterprise phone number to contact QuickBooks enterprise help team anytime & anywhere.
ReplyDeleteThe services of QuickBooks Premier Support Phone Number
ReplyDeleterequires one or two hours minutes in order to connect and provide the remote access support, then, the CPA will log into the customer's QuickBooks to teach customers, review the consumer's publications and, if suitable, input alterations and adjustments and will fix your errors.
QuickBooks updates are important for the smooth running of software. However, updates constantly come with fixes, patches, and bugs. So, if you are experiencing any type of issues in the installation of the latest QuickBooks updates, then contact our QuickBooks customer support expert team. Get-in-touch with our QuickBooks Support Phone Number team by dialing our toll-free number. Once you get in touch with us, our best support technician shall guide you in the Setup process in step-by-step.
ReplyDeleteThis comment has been removed by the author.
ReplyDeleteQuickBooks Tech Support Number is assisted by our customer support representatives who answer your call instantly and resolve all your valuable issues at that moment. It really is a backing portal that authenticates the users of QuickBooks to perform its services in a user-friendly manner.
ReplyDeleteThe technical QuickBooks support teams who work night and day to resolve QuickBooks related queries are trained to tune in to the errors, bugs, and glitches which are reported by a person and then derive possible ways to clear them. The QuickBooks Support Phone Number is toll-free and also the professional technicians handling your support call may come up with an instantaneous solution that may permanently solve the glitches.
ReplyDeleteThe QuickBooks Desktop Support Number is available 24/7 to offer much-needed integration related support also to promptly take advantage of QuickBooks Premier with other Microsoft Office software packages.
ReplyDeleteThe QuickBooks Tech Support Phone Number is supplied by technicians that are trained from time to time to meet with any kind of queries linked to integrating QuickBooks Premier with Microsoft Office related software.
ReplyDeleteThere are many reasons behind a QuickBooks made transaction resulting in failure or taking time for you to reflect upon your account. QuickBooks Support Phone Number can be obtained 24/7 to provide much-needed integration related support. Get assistance at such crucial situations by dialing the QuickBooks support phone number and let the tech support executives handle the transaction problem at ease.
ReplyDelete
ReplyDeleteQuickBooks accounting software is the most effective accounting software commonly abbreviated by the name QuickBooks Support Phone Number used to control and organize all finance-related information properly. Reliability, accuracy, and certainly increase its demand among businessmen and entrepreneurs. It really is a fantastic money management system for numerous companies all over the world.
Also, the reason for it’s popularity is not just the diverse features but also the customized support offered by QuickBooks Help Number and this makes it convenient to use this software. Another reason for gaining high level of popularity is that this software is much reliable. Problems with the accounting software never happen. Moreover, if they do, they are generally very simple to deal with! Certainly when you have most knowledge on the subject. When you don’t, there is yet still nothing to worry – Just check for the help from those who have this knowledge. Here, we are talking about staff or the experts from Quickbooks payroll support team.
ReplyDeleteThank you so much for the great and very beneficial stuff that you have shared with the world.
ReplyDeleteBangalore Training Academy is a Best Institute of Salesforce Admin Training in Bangalore . We Offer Quality Salesforce Admin with 100% Placement Assistance on affordable training course fees in Bangalore. We also provide advanced classroom and lab facility.
The most common errors faced by the QuickBooks users is unknown errors thrown by the QuickBooks Support Phone Number at the time of software update. To be able to fix the problem, you should look at your internet and firewall setting, web browser setting and system time.
ReplyDeleteQuickBooks Error Code 80070057
QuickBooks Install Diagnostic Tool
Thanks for sharing such a great blog Keep posting.
ReplyDeletecrm software
company database
database provider
all India database
buy database for marketing
database marketing
list of email ids of companies
list of mnc companies in delhi ncr with contact details
sales automation tools
sales automation process
sales automation CRM
sales automation
Best realtor in Brampton
ReplyDeleteBest Real estate agent in Toronto
Realtor Piyush is a one of the best real estate realtor in brampton. We have more than 10+ years of experience in this field. We are specializes in buying, selling, leasing and investing in properties of Brampton. We also cover wide area of field Mississauga and around many places.
Very nice vector tutorial. you have explained it very well . There is also good java vector tutorial Click Here
ReplyDeleteThe Silveredge Casino perform extremely well with its regular promotions and a wide range of silveredge casino games online. Thanks you for very nice its sharing. keep it up
ReplyDeleteAi & Artificial Intelligence Course in Chennai
PHP Training in Chennai
Ethical Hacking Course in Chennai Blue Prism Training in Chennai
UiPath Training in Chennai
It’s great to come across a blog every once in a while that isn’t the same outdated rehashed information. Wonderful read! I’ve saved your site and I’m including your RSS feeds to my Google account.
ReplyDeleteHow to Improve QuickBooks Software Performance
How to Transfer QuickBooks to New Computer
How to Create & Delete Budget in QuickBooks Desktop?
Wonderful post..you have explained it very well .Thank you for updating such a beautiful blog .
ReplyDeletesap training in chennai
sap training in tambaram
azure training in chennai
azure training in tambaram
cyber security course in chennai
cyber security course in tambaram
ethical hacking course in chennai
ethical hacking course in tambaram
Much needed useful information.
ReplyDeleteweb designing training in chennai
web designing training in annanagar
digital marketing training in chennai
digital marketing training in annanagar
rpa training in chennai
rpa training in annanagar
tally training in chennai
tally training in annanagar
You just share the main information that really needed thanks to keep writing good work.
ReplyDeleteFix Common QuickBooks Enterprise Errors
Supported Versions of QuickBooks Desktop on Windows 10
system requirements for QuickBooks desktop enterprise 2019
Great post!I am actually getting ready to across this information,i am very happy to this commands.Also great blog here with all of the valuable information you have.
ReplyDeleteacte reviews
acte velachery reviews
acte tambaram reviews
acte anna nagar reviews
acte porur reviews
acte omr reviews
acte chennai reviews
acte student reviews
I love your article so much and I appreciate your thought and views. This is really great work. Thank you for sharing such a useful information here on the blog.
ReplyDeleteInstall QuickBooks Desktop | QuickBooks File Doctor | QuickBooks Error Code H505
Nice Blog !
ReplyDeleteFor managing accounting tasks, you should use QuickBooks accounting software.In case you have faced any technical issues in QuickBooks, call us at QuickBooks Phone Number 1-855-974-6537.
Nice & Informative Blog !
ReplyDeleteQuickBooks is an easy-to-use accounting software that helps you manage all the operations of businesses. In case you want immediate help for QuickBooks issues, call us on QuickBooks Customer Service 1-855-974-6537.
Sage 50 year end not responding
ReplyDeleteSage 50 network installation on work station
Sage 50 2021 installation on work station
qbdbmgrn not running on this computer
create a new sage id login and what is sage id
QuickBooks desktop and QuickBooks online
Great Information and we love this post. keep up the good work thanks.You can see good collection of arraylist example visit Java ArrayList Example
ReplyDeleteNice & Informative Blog !
ReplyDeleteDirectly place a call at our QuickBooks Phone Number, for instant help.Our experts are well-trained & highly-qualified technicians having years of experience in handling user’s complexities.
Quickbooks file doctor is fixing programming to fix the record related issues in Quickbooks, for instance, Network Diagnostic blunders, Window issue, data pollution, etc The QB document specialist recognizes and settles the mistake from the Quickbooks record at the most punctual chance.
ReplyDeleteWhen you open a desktop and you login into the quickbooks account at that time you face some errors in the login activity which is known as quickbooks login error.
ReplyDeleteNice information thank u so much for it... Quickbook is an accounting software for small and mid type of buisness but day before yesterday i found some error in it quickbook error 6175 but right now the problem is resolved so u can go through it...
ReplyDeleteThank u...
Highly informative article. This site has lots of information and it is useful for us. Thanks for sharing . micro nutrient for plant growth
ReplyDeleteNice Blog, QuickBooks is well-known accounting software, and if you work in the accounting field, you've probably heard of it. QuickBooks Error 9999 is a script error that might prevent your bank and QuickBooks Online from connecting to the internet. The system hangs, responds slowly, or simply stops working when this issue occurs. When you try to update your bank information in QuickBooks, you get a banking error.
ReplyDeleteQuickBooks Error 1603 is the error that occurs while QuickBooks is installing on a Desktop computer. If you error code 1603 coming across your way, well, then i would suggest you to follow the guide where we have explained How to resolve QuickBooks Desktop error 1603 with ease. For further discussion, you can also connect with our experts at 800-579-9430.
ReplyDeleteWhen you try to restart a backup or when you try to upgrade the company file, you might encounter Quickbooks error 105.
ReplyDeleteWhat are the reasons which result in the occurrence of Quickbooks error 6123,0?
Program file may be damaged.
Web bugs blocked from antivirus may cause this error.
Operating system may be damaged.
Multiple Quickbooks versions being used.
Hosting Quickbooks company files might have been changed.
Nice blog, thank you for sharing your insights.
ReplyDeleteMulesoft Online Training
Mulesoft Online Training in Hyderabad
Hey,
ReplyDeleteIf you own a small retail business, you should know QuickBooks POS. It can streamline that inconvenient process. This hardware and software combo includes everything you need to ring up sales and print receipts. To Read Full Advantages of Quickbook Point of sale ←← Click Here
why are mountain bikes so expensive
ReplyDeleteThis is the perfect blog !! If you are searching for Quickbooks Information then click at
ReplyDeleteQuickbooks Customer Service +1 757-751-0347
Great Content ! . If you need help with your Quickbooks Software then you can Dial our team at Quickbooks Customer Service+18553777767
ReplyDeleteVery nice Blog! If you're looking for a reliable e QuickBooks accounting software, then dial Quickbooks Customer Service+1 267-773-4333
ReplyDeleteThis comment has been removed by the author.
ReplyDelete
ReplyDeleteIn today's modern world, where electricity is an integral part of our lives, having a reliable power conversion system is crucial. Whether it's for residential or commercial use, an inverter plays a vital role in converting direct current (DC) into alternating current (AC). best Solar Inverters Sungarner inverter, a highly efficient and innovative solution for power conversion needs.
DeleteIn today's modern world, where electricity is an integral part of our lives, having a reliable power conversion system is crucial. Whether it's for residential or commercial use, an inverter plays a vital role in converting direct current (DC) into alternating current (AC). best Solar Inverters Sungarner inverter, a highly efficient and innovative solution for power conversion needs.https://www.sungarner.com/products/solar-inverters/sunbee-l.php
"QuickBooks migration failed unexpectedly" is a concise statement that describes an unsuccessful attempt to transfer data from one QuickBooks version to another or from a different accounting software to QuickBooks. The migration process involves moving critical financial data, customer records, and other vital information to ensure seamless operations. However, encountering this error indicates that the migration was interrupted or encountered a problem, resulting in an unexpected failure.
ReplyDeleteThe reasons for this failure can vary, including data format incompatibility, version conflicts, data corruption, or network interruptions. To address the issue, it is crucial to identify the underlying cause and work with QuickBooks support or IT professionals to resolve the migration problem. A thorough troubleshooting process is essential to ensure successful data transfer, prevent data loss, and maintain accurate accounting records.
If you want to know more about QuickBooks then Dialing
ReplyDeleteQuickBooks customer service +1 267-773-4333 to get help from QuickBooks Expert
QuickBooks is a premium accounting software For more info contact our support team to get instant assistance at
ReplyDeleteQuickbooks customer service +18553777767
If you need to technical support For any QuickBooks Issue then get instant help at
ReplyDeleteQuickBooks Customer Service Phone Number +1 855-675-3194